Edge computing (computação de borda): o que é e para que serve
Introdução
Falamos em computação nas nuvens quando dados são acessados em um dispositivo (como o seu celular), mas processados em algum "lugar da internet". E se esse trabalho for realizado por computadores fisicamente próximos do usuário? Essa ideia é a base do conceito de edge computing ou, em bom português, computação de borda.
Nas próximas linhas, você vai ter uma noção mais clara do que é edge computing, conhecer algumas de suas aplicações e compreender a sua relação com a internet das coisas.
Se preferir, acesse diretamente um dos tópicos a seguir:
- O conceito de edge computing
- Computação de borda e computação nas nuvens
- Diferenciais da edge computing
- Computação de borda e internet das coisas
- Mais exemplos de aplicações para a computação de borda
- Computação de borda e fog computing
- Possíveis desvantagens da edge computing
O conceito de edge computing
Podemos entender a ideia de edge computing como um conceito que prevê que o processamento ou o armazenamento de dados seja feito tão próximo quanto possível do local em que eles são gerados ou utilizados.
Com isso, tem-se uma redução ou até a mesmo a eliminação de problemas oriundos da grande distância entre o dispositivo que acessa os dados e aquele que os armazena ou processa.
Um desses problemas é o aumento da latência, isto é, do intervalo de tempo que um dado leva para ser enviado de um ponto a outro. Via de regra, quanto menor a latência, melhor: quando esse parâmetro está elevado, a aplicação pode demorar mais tempo do que o razoável para ser concluída ou o usuário pode se deparar com inconsistências no serviço.
O aspecto da latência é tão importante que muitos serviços online contratam redes de distribuição de conteúdo (CDN, de Content Delivery Network) para que estas mantenham cópias de seus dados em serviços geograficamente mais próximos dos usuários. A Netflix é um exemplo de empresa que utiliza CDN para evitar, tanto quanto possível, que seus clientes enfrentem gargalos ao assistirem aos vídeos da plataforma.
Pelo menos até certo ponto, podemos considerar um serviço de CDN como um tipo de edge computing. Mas a computação de borda vai além disso, pois o conceito consegue aproximar ainda mais o processamento ou o armazenamento de dados da origem destes.

Computação de borda — imagem ilustrativa: Geralt/Pixabay
Computação de borda e computação nas nuvens
A computação de borda pode ser mais facilmente compreendida se a compararmos com a computação nas nuvens. Não, ambos os conceitos não se opõem. Na verdade, eles se complementam. Percebemos isso justamente na comparação de suas características.
A computação nas nuvens (ou cloud computing) consiste na disponibilização de serviços computacionais dos mais variados tipos a partir da internet.
Pense, por exemplo, em uma plataforma de e-mail como Outlook.com ou Gmail. Você pode acessar a sua conta em um desses serviços a partir do celular ou de um computador, de qualquer lugar do mundo, basta ter acesso à internet.
Os dados da sua conta são processados e armazenados em servidores remotos — nas nuvens — e, especificamente no caso de e-mails, não é necessário contar com baixa latência para usufruir dela — se você precisa de comunicação instantânea, deve utilizar um serviço de chat ou videoconferência, por exemplo.
Agora, pense em uma fábrica que conta com diversos sensores e equipamentos para controlar a produção. Se esses dispositivos tiverem que enviar dados para serem processados nas nuvens, a latência resultante desse processo pode reduzir a produtividade ou, em situações extremas, gerar interrupções temporárias.
Mas, se o processamento do controle da produção for for feito localmente por meio de uma solução de edge computing, a latência será mínima, talvez inexpressiva. A produtividade tende a melhorar e o risco de problemas por falhas de comunicação com as nuvens deixa de existir.
Tem mais: nem sempre a computação nas nuvens precisa ser abandonada; servidores locais podem se comunicar com a nuvem da empresa para reportar os avanços da produção de forma que a matriz tenha informações sempre atualizadas da produtividade de cada uma de suas fábricas, por exemplo. Como já dito, ambos os conceitos podem se complementar.
Isso significa que a edge computing consiste apenas no processamento local de informações? Na verdade, a proposta do conceito é mais ampla do que isso, como deixa claro o próximo tópico.
Diferenciais da edge computing
O que diferencia a edge computing de uma rotina convencional de processamento local é a integração: a computação fica na borda de uma rede, de modo a se comunicar com os diferentes serviços e dispositivos que a compõem, sempre que necessário.
A lógica é a de "dividir para conquistar": em vez de um datacenter local ou um serviço nas nuvens centralizar todo o processamento de uma aplicação, esse trabalho é dividido em "pequenos datacenters", por assim dizer, de modo que cada um deles possa se dedicar a atividades específicas e se comunicar com os demais para a integração dos resultados.
Voltando ao exemplo da fábrica, um servidor pode responder pela distribuição de componentes, outro pelo controle de qualidade, um terceiro pela separação de produtos para embalagem e assim por diante.
Os dados de todos os computadores podem então ser enviados para um servidor que controla a demanda e a oferta que, por sua vez, se comunica com um serviço nas nuvens que monitora a produção de todas as fábricas da companhia ou ajuda na tomada de decisões por meio de Big Data.
Com base nesse exemplo, podemos notar algumas vantagens do conceito:
- diminuição da latência, pois grande parte do processamento está no ambiente de produção;
- redução dos custos com tráfego, pois apenas dados já processados são enviados às nuvens;
- redução de custos com processamento externo, pois menos dados são tratados nas nuvens;
- mais controle sobre a segurança, pois o fluxo externo de dados é menor;
- menor risco de interrupção de atividade, pois é mais fácil substituir um servidor defeituoso que atua em uma tarefa específica do que um sistema centralizado que, como tal, pode ser completamente paralisado em caso de problemas técnicos.
Outros benefícios incluem escalabilidade (capacidade de os recursos computacionais serem expandidos para atender a um aumento de demanda) e possibilidade de aproveitamento de diversos tipos de dispositivos, como celulares e computadores pessoais. Esse aspecto nos leva a outros conceito importante: o de internet das coisas.
Computação de borda e internet das coisas
Temos aqui no Infowester uma explicação completa sobre internet das coisas, mas eis o "resumo resumido": o conceito descreve dispositivos que se tornam "inteligentes" ao se comunicarem automaticamente com outros por meio da internet ou rede local.
Talvez você use um dispositivo que se encaixa na ideia de internet das coisas (conceito também conhecido pela sigla em inglês IoT) e nem sabe: smartwatches, smart TVs, termostatos gerenciados por aplicativo, alto-falantes com assistente de voz e câmeras de vigilância inteligentes são ótimos exemplos.
A IoT vai muito além dos limites da sua casa: o conceito também encontra aplicação na indústria, no setor de serviços, no agronegócio e assim por diante. É neste ponto que a computação de borda e a internet das coisas podem ser combinadas.
Não é por mero capricho: alguns dispositivos que se enquadram no conceito de IoT, mesmo que tecnicamente simples, podem processar determinadas tarefas individualmente ou em conjunto com outras unidades; em outros casos, esses dispositivos podem se comunicar com pequenas centrais de processamento fisicamente próximas. Temos, em ambos os casos, a edge computing ganhando forma.
Na verdade, sem a computação de borda, soluções baseadas em internet das coisas seriam permanentemente dependentes da computação nas nuvens ou de datacenters para funcionar, o que nem sempre é viável.
Como exemplo, imagine uma fazenda que utiliza sensores (que correspondem a dispositivos de internet das coisas) para medir temperatura e umidade do solo em tempo real e, quando for o caso, acionar o mecanismo de irrigação de água.
Em grandes áreas rurais, nem sempre é possível manter uma estrutura de acesso à internet para esse serviço funcionar; uma alternativa pode ser a implementação de um sistema local baseado em edge computing que mantém contato com os sensores e ativa a irrigação de água no momento certo.
Depois, esse sistema pode repassar os dados dessas ações para um servidor online que possibilita aos administradores acompanharem o desenvolvimento do plantio, não importa o lugar em que estejam.

Edge computing — imagem ilustrativa: Geralt/Pixabay
Mais exemplos de aplicações para a computação de borda
No decorrer do texto, você viu exemplos de aplicação de edge computing na indústria e na agricultura. Mas o conceito encontra utilidades em diversas outras áreas. Então, vamos a mais alguns exemplos:
- Hospitais e clínicas: a computação de borda pode ser útil para agilizar o processamento de exames médicos ou no monitoramento de pacientes por meio de dispositivos vestíveis (oxímetros, monitores de frequência cardíaca, entre outros);
- Trânsito de veículos: com auxílio de câmeras e sensores, a computação de borda pode ser usada para otimizar o tempo de fechamento de semáforos de modo a melhorar o fluxo de veículos em determinada região;
- Transporte público: dispositivos podem ser utilizados para monitorar o fluxo de passageiros em estações ou pontos de embarque de modo a permitir que a frota ativa de ônibus ou trens de um sistema de transporte público seja ajustada de acordo com a demanda;
- Educação: tecnologias de computação de borda podem ser aplicadas a ferramentas digitais de apoio à educação, a exemplo de sistemas de ensino baseados em realidade virtual;
- Varejo: sensores e câmeras podem ser usadas para medir a retirada de produtos das prateleiras de uma loja e alertar para a necessidade de reposição de itens ou de nova precificação de produtos que estão tendo baixa saída.
Computação de borda e fog computing
É possível que você encontre a associação de edge computing com fog computing — algo como "computação em neblina", em tradução livre. Na primeira olhada, os dois conceitos são equivalentes entre si. Mas um vislumbre mais profundo deixa claro que há algumas diferenças entre eles.
Uma arquitetura de fog computing não está tão na borda quanto uma solução de edge computing, por assim dizer, da mesma forma que não está tão nas nuvens quanto um sistema de cloud computing.
Essencialmente, a computação de borda permite que dispositivos participantes da rede ou equipamentos próximos a esta processem ou armazenem dados. Já o fog computing permite que componentes que estão mais distantes, como pequenos sistemas baseados nas nuvens ou servidores instalados em prédios vizinhos, componham a rede.
Mas, de novo, não é incomum a edge computing e a fog computing serem tratadas como conceitos equivalentes, afinal, ambas têm o mesmo propósito: levar mais inteligência e agilidade de processamento para o local que gera os dados.
Outra razão é o fato de a denominação fog computing ter sido cunhada pela Ciscos em 2014 e, portanto, ser considerada uma espécie de marca registrada da companhia (embora não o seja).
De modo geral, fica mais fácil reconhecer e tratar a fog computing como um tipo de computação de borda.
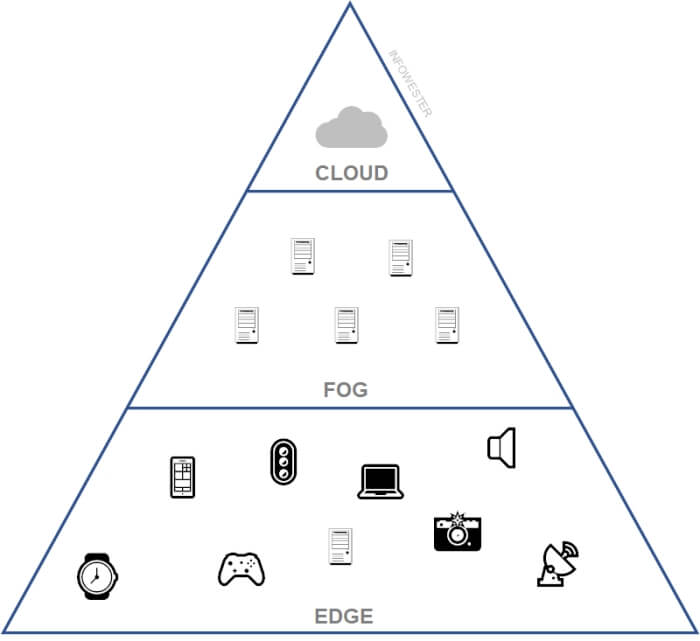
Cloud, fog e edge computing
Possíveis desvantagens da edge computing
Até aqui, você conferiu explicações sobre o conceito de edge computing e conheceu algumas de suas vantagens. Assim, fica parecendo que a computação de borda é a solução para todo e qualquer tipo de aplicação.
Não é bem assim. A escolha por uma solução do tipo deve ser bem ponderada, pois algumas desvantagens podem existir. Eis alguns exemplos possíveis:
- Compatibilidade: equipamentos ou sistemas já em uso podem não ser compatíveis com uma solução de edge computing, exigindo adaptações ou atualizações custosas;
- Segurança: alguns dispositivos, principalmente no universo da internet das coisas, podem trabalhar com camadas de segurança frágeis que, como tal, expõem o sistema parcial ou totalmente;
- Complexidade: soluções de edge computing consistem, essencialmente, em sistemas distribuídos (formados por muitos dispositivos); esse tipo de arquitetura tende a ser mais complexa e, novamente, custosa;
- Manutenção: a variedade de dispositivos que compõem a rede pode exigir esforços adicionais para manutenção física, atualização de softwares e correção de problemas.
Um bom mapeamento das necessidades operacionais do negócio e a escolha das soluções mais adequadas a elas podem atenuar ou até eliminar a possibilidade de esses problemas se manifestarem.
A escolha de uma empresa de TI especializada no assunto é o primeiro passo para isso. Além do trabalho de mapeamento, a companhia poderá oferecer equipamentos apropriados para edge computing, recomendar provedores de soluções específicas, fornecer treinamento, entre outros.
* * *
Você pode saber mais nas páginas que serviram de referência para este texto:
Publicado em em 25_03_2022.
 Autor: Emerson Alecrim
Autor: Emerson Alecrim
Graduado em ciência da computação, tem experiência profissional em TI e produz conteúdo sobre tecnologia desde 2001.
É especializado em temas como hardware, sistema operacionais, dispositivos móveis, internet e negócios.
Principais redes sociais:
• X/Twitter
• LinkedIn